11 Ways to Reduce Ediscovery Expenses
It’s impossible to overlook the transformative effects that widespread digitalization continues to have on the landscape of legal work—in particular, our relationship to information. Between the steadily compounding volume and complexity of data and the evolving regulatory landscape surrounding its management, legal professionals increasingly require efficient, future-oriented solutions that won’t become antiquated after the next big technological advancement. More than manifesting as a series of operational bottlenecks, the evolution of technology and its impact on legal work are creating a significant financial strain on legal teams and organizations.
After reviewing thousands of cases in which ediscovery processes were of central importance, Santa Monica, California, think tank RAND found that ediscovery costs take up to 40% of litigation budgets, with 75% of those funds used on review-related tasks. These costs will double over the next five years, and we have already reached the point at which 99% of potentially relevant data is digital. Additionally, this need to update processes and cut costs on ediscovery will only be made more urgent by the introduction and refinement of new data privacy laws in the US and Europe.
In this guide, our goal is to emphasize the benefits of sophisticated digital solutions for reducing ediscovery costs, particularly production- and review-related expenses.
[Editor’s Note: This piece was originally published in October, 2021. It has since been updated with additional information, including a new section on leveraging generative AI to reduce ediscovery expenses.]
Category 1: Reviewing Fewer Documents
Before legal teams address the complexity of modern data, they first need to confront the increasingly high volume of electronic information that’s sure to be associated with almost any case. While each matter is different, teams often have an obligation to review anywhere from hundreds to millions of documents, which can be a considerable challenge for even the most capable and sizable operations. To reduce the volume of documents up for review, administrators and their teams can rely on the following strategies:
Reduce review costs at the onset through Early Case Assessment
ECA refers to certain tools and methods used by legal teams to reduce data volume before the reviewal process even begins. By gaining critical insights into the nature of the data, identifying and eliminating duplicate documents, and optimizing the ability to search for relevant information using keywords, legal teams can simultaneously cut ediscovery costs on data storage and make the actual review process more efficient. Traditionally, ECA tools utilize an “in-out” strategy. First, data goes into a processing tool for extraction, deduplication, and deNISTing (a specific method for eliminating invaluable data based on file type). The “in-out” strategy allows legal teams to search through text and metadata more easily based on keywords and, ultimately, to cull or pull out any documents that likely won’t be useful to the case. Once the entire ECA process is complete, the culled data will be stored separately so that it reduces the volume of documents in the review space but can still be accessed as needed.
Everlaw’s platform builds on the traditional ECA strategy in two critical ways. First, in addition to text and metadata, our processing tool also extracts the images and native files associated with documents. In our experience, images and native files provide much more intuitive insights into the data contained in the ECA space, reducing the level of technical know-how necessary to navigate the data pool or understand the complexities associated with metadata. Secondly, instead of housing culled documents in a siloed location, Everlaw’s ECA space is directly linked to the review space so that anyone with access to both can move easily between the two, promoting and demoting documents efficiently based on their immediate usefulness.
Utilize passive learning tools through data visualization and concept clustering
Taking advantage of passive learning technologies is another reliable way to reduce the number of documents requiring review. While the phrase “passive learning” is an umbrella term that can refer to a variety of digital solutions, for our purposes it simply refers to any method or tool that can provide an overview of documents without the need for any user input.
At Everlaw, we utilize two specific methods to help legal teams passively identify irrelevant data and focus only on the documents that matter: data visualization and concept clustering.
Data visualization can be used to produce an illustration of text and metadata once the documents have been collected and processed. The data is visualized along several key dimensions, including dates, file types, custodians, subject lines, and correspondence fields. This allows legal teams to identify certain patterns in the data pool, such as recurring dates, subject lines, and recipients, without needing to manually review the data. Additionally, any irrelevant data can be promptly removed from the review set, and the process can even be automated to prevent similarly irrelevant data from showing up later on. When utilized to its full potential, data visualization can save legal teams hours, or even days, on first-level review work.
Document clustering, or “concept clustering,” helps legal teams identify patterns that aren’t as easily revealed through the simple visualization of metadata. Through the use of modern algorithms, large document collections can be parsed and automatically sorted into “clusters” based on higher-level themes found in the data’s text and metadata. For example, one cluster might contain documents related to environmental research, whereas another might be dedicated to office management. Through this process, legal teams can easily identify both relevant and irrelevant themes and prioritize the corresponding data accordingly.

Determine key terms using search term reports
By the time documents have been collected, parties often have an initial sense of which words or phrases will be central to a case. Once the passive learning tools clarify the nature of the data, legal professionals can narrow down document review obligations by creating a series of dynamic search term reports. These reports help legal teams zero in on which terms bring back a disproportionate number of documents and where legal professionals should focus during review. Teams that have the ability to produce thorough, far-reaching search term reports in a timely manner can end up with a significant advantage, and in some cases, the results can lead to a renegotiation of terms to avoid overly burdensome review obligations.
With the Everlaw platform, search term reports are automated and can be updated with the click of a button to include new terms as the case progresses, significantly reducing the time administrators spend on managing new searches. The use of automation allows our reports to yield results instantaneously, neatly organized based on hits per term, or based on a more targeted approach, such as specific hit counts related to an individual document. The speed of Everlaw’s search functionality (search results are returned at a median speed of 7 milliseconds), combined with its complex and customizable search functions based on individual criteria, allows legal teams to save considerable time producing reports.
Identify the most inclusive emails
Since emails are a primary form of communication today, they often contain invaluable information that can help legal teams develop their case. While a single email has the entirety of the historical conversation (in the form of a “thread”) embedded in it, many of the individual messages contained in the thread will be of little to no use. By identifying the “most inclusive” email within each thread (i.e., the message containing the most relevant information), legal teams can eliminate the need to read each message more than once, reducing the volume of emails necessary to review by upwards of 30%.
With Everlaw, legal teams can automate searches to include only the most inclusive emails from the outset of the process while maintaining the ability to review the less inclusive documents at a later time, if necessary. Even when conversations branch off into separate threads—which happens frequently—users can customize to identify and organize multiple related “thread groups” at no additional cost.
Category 2: Optimizing Review Processes for Efficiency
Even after reducing the overall volume of potentially relevant data, there are still several subsequent tasks within the actual review process that modern technology can optimize. In order to further cut costs and increase the efficiency of per-document review, administrators and their teams can do the following:
Utilize predictive coding to avoid manual review of some documents
Reviewing each document individually throughout the ediscovery process is increasingly less viable in the age of electronic information. In order to remain even minimally productive, legal teams often need to adopt concrete methods to avoid performing manual review whenever possible. Predictive coding or technology-assisted review (TAR) is one of the most intuitive and straightforward approaches to speeding up review times without the risk of overlooking potentially critical information.
Predictive coding is a form of machine learning, a technology that most of us are quite familiar with whether we realize it or not. In fact, if you have an account with Netflix, Spotify, YouTube, or any other major streaming service, then you probably interact with machine learning systems on a fairly regular basis. And in very much the same way Netflix can identify the kind of movies and TV shows you prefer, Everlaw’s technology can identify the information that legal teams believe will be most relevant to win their case. Predictive coding works by using a categorization process. After utilizing the above methods to learn as much as possible about which information is likely to be most relevant, legal teams can feed what they’ve learned into a predictive coding algorithm. Once the legal team establishes an accurate model of preferences, the algorithm can identify documents based on preferred categories and even flag documents with similar characteristics that might otherwise have been overlooked.

Predictive coding can radically reduce the number of documents necessary to review manually by automatically prioritizing the information that is likely to be the most relevant. Importantly, not all predictive coding technologies have the same functionality. There are still a number of legacy systems on the market that rely on an outdated, rigid methodology consisting only of training the model before review. With these systems, the algorithm will identify documents based on manually established categories, but it won’t have the capacity to continuously learn and adapt throughout the review process.
With Everlaw, not only is the algorithm continuously learning, but it is also constantly assessing its own performance through a process of recall and precision. Over a short period of time, the number of documents correctly predicted to be relevant (recall) and the number of relevant documents returned (precision) will become sufficiently reliable. Overall, predictive coding is one of the most efficient ways to properly assign documents to batches based on categories and relevancy, greatly simplifying whatever manual review efforts legal teams can’t avoid. And in the most successful cases, predictive coding can significantly expedite the entire review process by identifying the most critical information early on, eliminating the need to manually review hundreds of irrelevant documents and ensuring that teams have the most important documents on hand to support their case.
Auto-code related documents
After using predictive coding to organize documents into batches based on categories and relevancy, legal teams can set up the actual review process for further efficiencies with the addition of auto-code rules. Because documents rarely exist in isolation and are almost always directly related to other documents (e.g., messages in an email thread, file attachments, or duplicates), it’s important to clearly understand which documents contain duplicate information so as to not waste time or resources. For example, hundreds of employees may have received the same PDF attachment of a corporate memo but not all within the same email thread. By applying an auto-code to the attachment, legal teams can avoid having to review the same memo over and over again in a series of maddening loops.
Users can set up auto-code rules on a project level or during the normal course of review, and Everlaw allows administrators to determine and manage who can apply these codes through an intuitive permissions interface. Moreover, Everlaw’s auto-code review speed clocks in at 140 documents per hour, or 180% faster than the industry standard. When utilized correctly and with full consideration of a legal team’s risk and cost balance, eliminating multiple duplicates from the review process can lead to improved efficiencies.
Decrease doc-to-doc and page-to-page load times
Of course, if the above processes aren’t operating from a foundation of responsive technology, then legal teams won’t be able to utilize them to their full potential. And the unfortunate truth is that far too many legal professionals today are still left groaning at their computer screens as they wait for a document to load, an experience that is as frequently frustrating as it is unnecessary.
Everlaw utilizes modern, cloud-native technology that scales incredibly well, dynamically allocating the resources needed to keep review moving along swiftly and without interruption. To introduce a useful analogy, scaling in the cloud is somewhat akin to the functionality of newer combustion engines, which produce efficient horsepower by automatically turning cylinders on and off as they work. The only flaw in this example is that the amount of horsepower an engine can produce has a hard limit, whereas the cloud has the equivalent of infinite horsepower, allocating as many resources as necessary at no additional cost. This can save legal teams hundreds of hours in review compared to traditional technologies, some of which still suffer from multisecond load times.
Technical analogies aside, legal professionals don’t actually need to understand how cloud-native scaling works to realize that waiting for a document or page to load for even more than a second is unacceptable by today’s standards. As a rule, it should take well under 350 milliseconds for any page or document to load, or in other words, much faster than anyone can blink. Everlaw’s use of cloud-native technology, in addition to our intuitive interface, has allowed us to achieve a baseline review speed of 86 documents per hour, or 72% faster than the industry standard.
Category 3: Reducing Risks with Built-In-Automation
Some mistakes are always inevitable, but there are a number of strategies that can be employed to reduce the impact of these mistakes as well as mitigate future risks. Administrators and their teams can effectively leverage Everlaw’s built-in automation technology to accomplish the following critical tasks related to risk management:
Illuminate dark data
Dark data is any piece of information that can’t be easily accessed or searched. It can manifest in a variety of ways, whether hidden in formulas in spreadsheets, speech in audio or video files, content written in a foreign language, and even in metadata from an email attachment. Invaluable information to a case can potentially be dark data, but for many legal teams, properly identifying and reviewing this information is either entirely impossible or unreasonably time-intensive.
Everlaw provides the various tools necessary to illuminate dark data at no additional cost. Users can use Everlaw’s advanced spreadsheet viewer technology, which is baked directly into the review platform, to uncover formulas and other hidden content. Additionally, machine transcription technology will automatically render any spoken language in media files searchable, and machine translation technology will convert foreign-language content into any language desired, effectively removing the need for a human translator. And finally, Everlaw automatically extracts email header information, providing dates, subjects, and correspondence information to enrich the search functionality of emails and PDFs that arrive without any accompanying metadata.
Automate assignment workflows
In almost all cases, document review is a collaborative process that often involves multiple stages, such as first- and second-level reviews. And while this is mostly an efficient approach, as it allows teams to divide responsibilities and remain productive across the board, it can also become inefficient very quickly if teams don’t execute handoffs in a timely fashion during critical points.
With the use of similar technology that allows legal teams to automate search term reports or use predictive coding to assign documents to batches, users can automate documents to move seamlessly from one review level to the next once a specific task is complete. When a user finishes the initial coding of a document, for example, the task is recorded as complete before immediately notifying the next responsible party that it is ready to be assigned to a batch. Automated workflows can be utilized from start to finish in order to greatly reduce and, in some cases, entirely eliminate time-consuming and costly lags in response times, ensuring that each document or task flows smoothly from stage to stage and that reviewers are always occupied with the most important work at all times throughout the process.
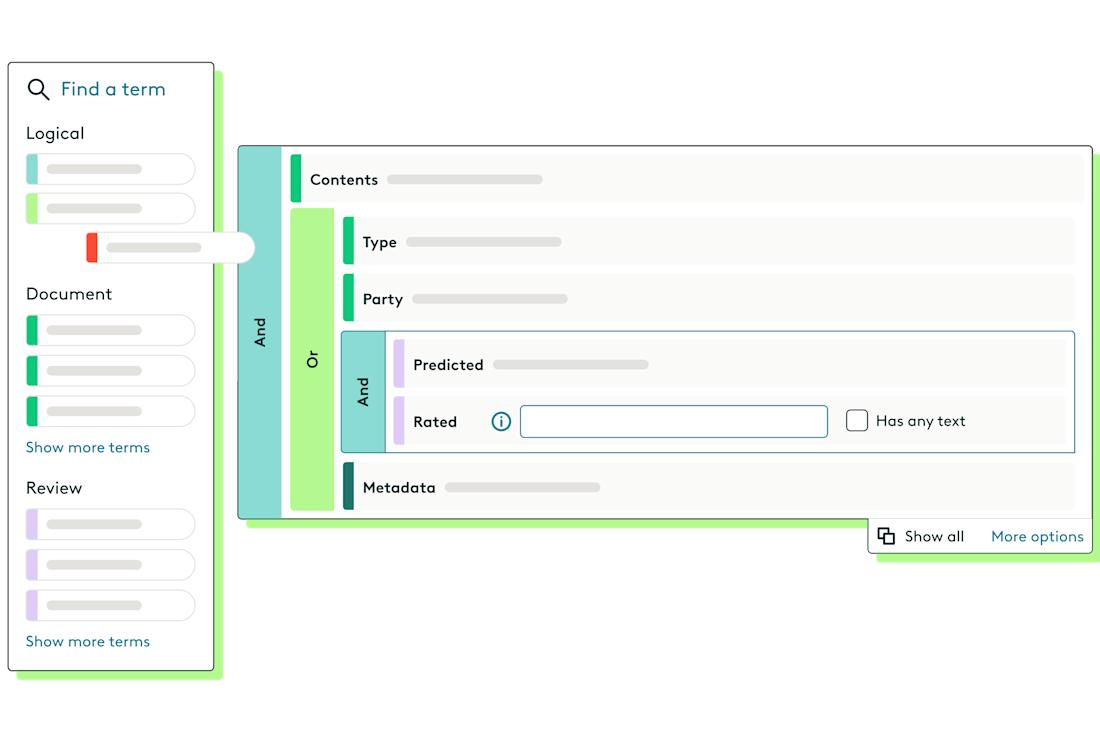
Conduct pre-production Quality Assurance (QA)
While all of the above methods should lead to a notably accurate, efficient, and thorough review process, there is almost always the possibility of there being an error in one area or another. Errors happen with even the most well-run, technologically capable legal teams, but fortunately, they can also be caught and mitigated by conducting a careful pre-production QA exercise. Without the use of automation, however, pre-production QAs can end up being another incredibly drawn-out and costly endeavor. There are many reasons for this, but it ultimately comes down to two factors: checking documents manually consumes a lot of time, leading to a higher possibility of repeated human error. The fact is that QAs need to be both rigorous and efficient, and the apparent opposition of these two goals can only be overcome by the introduction of automated checks.
Automation can remove much of the guesswork from the creation of a final disclosure set, and Everlaw has automated checks for pre-production QAs built directly into the platform. Instead of laboring over manual checks that are likely to produce additional errors, Everlaw’s automation tool will scan the entirety of documents. The automation tool notifies administrators of any missing information (whether it’s a privilege rule or a critical file contained in an attachment), identifies redactions or processing errors in spreadsheets and documents, and prevents the disclosure of duplicates. Utilizing automated checks can significantly lower the risk of disclosing the wrong documents in a final bundle or producing a bundle that unintentionally leaves out critical information. In addition to saving a lot of time on the back end of the review process, leaning into automation should provide legal teams with the confidence necessary to create and submit a final disclosure set without the fear of costly missteps or falling into a violation of the agreement.
Easily mimic these steps when reviewing disclosed data
Now that we have detailed various methods that legal teams can adopt to reduce costs and make review processes for ediscovery more efficient, let’s see how they can apply these exact same methods to reviewing incoming disclosures. After all, nobody wants to start from scratch when new documents are inevitably disclosed. Here’s how these methods can be applied to reviewing disclosed data, step by step:
When legal teams receive disclosed documents, they can load them to the ECA space rather than the review space. From there, teams can use the same searches used previously to identify and promote only the documents relevant to the review.
Once users promote all the relevant data to the review space, they can apply the same data visualization filters and update the document clustering analysis with the click of a button.
Next, the search term reports set up previously can be copied and pointed at the new data, eliminating the need to construct entirely new reports.
Once users upload the new documents, the most inclusive emails can be automatically culled based on the thread groups produced earlier—no need to backtrack.
With the predictive coding model already intact, the new data is automatically fed into the system without any modification to the original settings. The predictions made by the algorithm can then continue to generate and guide the review of new information, highlighting the most relevant documents first.
Since auto-code rules are already in place at this point, nothing needs to be done except to utilize them.
Finally, users can make a simple modification to the already established workflows to include the newly disclosed documents in the review pool, automatically prompting action without the need for an administrator to formally arrange for a review.
Category 4: Leveraging Generative AI to Further Reduce Costs
The principles of reducing data volume and optimizing review workflows are foundational to cost control in ediscovery. The emergence of generative AI introduces a new paradigm, moving beyond simple automation to augment the cognitive work of legal teams. EverlawAI Assistant integrates this technology directly into the platform, helping legal teams accelerate tasks that have traditionally been the most time-consuming and expensive. By handling the first pass of arduous tasks like summarization, document coding, and drafting, the AI Assistant frees up legal professionals to focus on higher-value strategic work, further driving down costs while increasing the quality of insights.
Accelerate understanding with AI-powered document summarization
A primary challenge in any matter is gaining a quick yet thorough understanding of a large document set. Manually reviewing documents simply to understand their substance is a significant cost driver. EverlawAI Assistant addresses this directly by generating narrative summaries of documents, a task that can be performed on individual files or in batches of up to 20,000 at a time.
For lengthy, dense documents, the assistant provides chunked summaries broken down by section, allowing reviewers to grasp the core concepts without reading every page. For shorter documents, a concise description is generated. This functionality radically reduces the initial time investment required to profile a new production or assignment. Instead of dedicating days to manual reading, legal teams can get a high-level overview of a document set in a fraction of the time. This immediate insight allows for more strategic allocation of human reviewers, who can bypass foundational review and focus their expertise on the most critical and nuanced documents from the outset, leading to direct cost savings.

Increase review efficiency with Coding Suggestions
Document review is consistently the most expensive component of ediscovery. EverlawAI Assistant’s Coding Suggestions feature targets this cost center by automating the crucial, yet repetitive, task of document coding.
Legal teams configure the assistant by providing instructions in plain English, including background on the case and the specific criteria for each code on the review protocol. The AI then analyzes documents and suggests whether a code should be applied, providing a rationale for each suggestion based on the document’s text. In internal testing, this feature has demonstrated accuracy comparable to, and often exceeding, first-level human review.
This capability delivers significant cost savings by reducing the person-hours required for manual review. A case study with an Am Law 100 firm found that Coding Suggestions allowed them to complete a 126,000-document review in less than half the time required by eyes-on human review and with accuracy rates outpacing human performance. By automating the initial coding pass, teams can focus their efforts on quality control and the analysis of more complex documents, substantially lowering review costs without sacrificing work product quality.
Streamline narrative creation with Writing Assistant
The ultimate goal of ediscovery is to build a compelling narrative for your case. The transition from document review to drafting arguments, memos, and deposition outlines is another area ripe for efficiency gains. Writing Assistant, part of the EverlawAI Assistant suite of tools, is integrated directly within Everlaw Storybuilder, acting as a dedicated partner in this process.
Legal teams can select curated sets of evidence within Storybuilder and instruct the Writing Assistant to generate initial drafts of work product. This can range from a factual background memo to a list of key themes or a table organizing critical events. The assistant produces structured content complete with citations back to the source documents, ensuring every point is verifiable. This jumpstarts the drafting process, transforming hours of manual fact compilation and organization into a task that takes minutes. By handling the initial synthesis of evidence, the Writing Assistant allows legal professionals to dedicate more time to refining arguments and developing case strategy, reducing the overall cost of work product creation and accelerating the path to resolution.
Conclusion
As overwhelming, complicated, and costly as the review and ediscovery process can be for legal teams today, many of the associated challenges and expenses are actually the result of using inadequate or outdated tools. Importantly, however, as electronic data continues to increase in both volume and complexity, and new rules surrounding ediscovery and regulations surrounding data privacy continue to emerge, existing issues with data management will only become more difficult for legal teams in the absence of more modern technological capabilities and processes.
The Everlaw platform has everything legal teams need to become more cost-efficient, and more importantly, to bring their ediscovery practices into the digital age.
In addition to providing the tools needed to implement a successful digital transformation, Everlaw illustrates a clear road map to utilizing our technology and realizing the full potential of each individual function. Between reviewing fewer documents, optimizing review processes for efficiency, and reducing risks with built-in automation, we have demonstrated a number of specific methods to considerably improve operational efficiency and subsequently reduce ediscovery expenses.
