Everlaw Blog
See what’s new at Everlaw and read the latest and greatest in legal tech and ediscovery.
See what’s new at Everlaw and read the latest and greatest in legal tech and ediscovery.

5 min read

Judges emphasized that while AI can improve efficiency, it requires human supervision, privacy protections, and high...
2 min read

The second in a series of conversations with Michael Sarich, former Director of FOIA at the...
7 min read

A Conversation with Michael Sarich, former Director of FOIA at the Department of Veterans Affairs.
7 min read

Jeffries v. Harcros Chemicals Inc. set a new precedent regarding the use of open-loop AI tools...
3 min read

The three-part series is designed to bring real-world AI skills and insights to the legal aid...
3 min read

Everlaw’s Joe Skalski discusses the true value of legal services in the AI era.
7 min read

Harlan Hillier DiGiacco LLP leverages Everlaw to help streamline workflows, manage metadata and ESI, and compete...
2 min read

Judge Maritza Dominguez Braswell spoke with Everlaw about AI guidance, the skills young attorneys should be...
13 min read

This Am Law 200 firm used Everlaw's Coding Suggestions tool to review nearly 600,000 documents, achieving...
5 min read

A partnership that helps clients succeed.
4 min read

What actually works and what defensibility really means when AI enters the discovery workflow.
5 min read

See how Coalfire’s in-house team gains command over data and delivery times.
4 min read

Hear how journalist Burt Helm used Everlaw to understand massive volumes of online video game data...
4 min read

Introducing Everlaw's new public records and FOIA request solution.
2 min read

Everlaw CTO Max Christoff on agentic AI's "breakout season" in law.
2 min read

Everlaw and Anthropic are bringing Claude to Everlaw data.
5 min read

Everlaw Legal Holds lets corporate legal teams preserve evidence with greater controv and isibility.
4 min read

This guide to HSR Second Requests details how AI and cloud ediscovery streamline FTC compliance and...
18 min read

A new partnership to connects litigators’ AI-powered workflows across two leading platforms.
2 min read

From manual marker-pen redactions to a pivotal role in landmark English litigation.
5 min read

Everlaw's Five-Step Guide to Change Management highlights how legal teams can lead human-centered change in their...
2 min read

Palo Alto Networks AGC discusses GenAI and Agentic AI for in-house legal.
7 min read

Learn key strategies for preventing spoliation.
7 min read

Five Ways Generative AI Is Reinventing Litigation: Move from data sifting to high-level strategy with the...
5 min read

See how tools like Deep Dive are changing the game for plaintiffs firms.
4 min read

Stephen Lee is a solo practitioner who leverages Everlaw to take on cases against larger competition.
4 min read

A recent decision in *Morgan v. V2X, Inc.* resulted in a modified protective order regarding the...
4 min read

See how this firm combined search, Coding Suggestions, and Predictive Coding for near perfect recall.
5 min read

See how NAAG empowers state AG offices with legal technology.
4 min read

See how Everlaw expedites DSAR responses for data protection, privacy, and compliance teams.
9 min read

London & Naor is a boutique firm based in Oakland, CA, that uses Everlaw to deliver...
2 min read

Judge Samuel Thumma sat down with Everlaw to discuss generative AI, access to justice, and more.
16 min read

Everlaw for Good has grown 74%, supporting 675+ cases across 235 organizations.
1 min read

See how the Adio + Everlaw together build stronger client relationships.
3 min read

Everlaw’s flagship customer event returns this October 27-29 in San Francisco.
1 min read

Hallett & Perrin leverages Everlaw to increase efficiency and collaboration, and analyze data more effectively.
3 min read

See how Right Discovery helps clients embed EverlawAI in key workflows.
2 min read

Two dozen+ publications highight findings from the Everlaw/ACC GenAI report.
6 min read

Everlaw's guide to mastering ediscovery offers a comprehensive look into the strategies for ensuring efficiency in...
2 min read

See how customers integrate GenAI into their litigation workflows.
4 min read

Deep Dive leverages generative AI to enable legal teams to ask questions of their litigation data...
2 min read

Continued success with GenAI calls for intentional conversations about how it's used for legal work.
4 min read

Hamilton Law Firm uses Everlaw to get their work done faster and compete against larger firms.
3 min read

The top ediscovery certification programs in 2026 can help advance your career.
5 min read

Managing ediscovery costs is more important than ever in 2026.
7 min read

Everlaw's Fact Management allows you to start building your winning argument from the first moments of...
3 min read

The UCSF Industry Documents Library leveraged Everlaw to help manage its large database of documents.
5 min read

Keep up with emerging technologies and connect with peers at these 2026 legal tech conferences.
4 min read

Leading judges discussed developments in generative AI, ediscovery, and more at Everlaw Summit '25.
5 min read

The Everlaw Summit Awards recognize leaders and innovators across the legal profession.
5 min read

See how this energy company reduces risks and costs by surfacing the right information with Everlaw.
5 min read

This AGC shares how Everlaw saves her legal team time and money on giant construction matters.
6 min read

Predictions for 2026 from thought leaders in the legal industry.
4 min read

Navigate the transition to the cloud while maintaining the security and accountability that public service demands.
2 min read
Deep Dive leverages generative AI to enable legal teams to ask questions of their litigation data...
4 min read

Jessica Wan, Partner at FCOP, on discusses Everlaw drives efficiency, cost savings, and supports their pro...
4 min read

Learn how 284 in-house legal pros expect GenAI to help them prove their strategic value to...
3 min read

Everlaw Summit '25 brought legal professionals to San Francisco for three days of inspiration, connection, and...
6 min read

Highlights from the Everlaw Summit '25 keynote.
9 min read

Justice Tanya R. Kennedy sat down with Everlaw to discuss these issues and more, including why...
11 min read

Find out how 657 corporate in-house legal chiefs expect GenAI to redefine internal operations and external...
3 min read

Follow these tips for prompting GenAI-tools like Coding Suggestions.
3 min read

A new report from Everlaw highlights how legal aid organizations are using AI to serve more...
2 min read
Max Christoff joins Everlaw as our first Chief Technology Officer.
4 min read

Discover how your organization can create a plan for its generative AI goals based on the...
5 min read

Adams and Reese uses Everlaw to continue elevating their ediscovery practice and instilling technological confidence in...
3 min read

The Everlaw Summit Awards recognize leaders in the ediscovery and legal technology space.
2 min read

See how Kelly Mickelson leads with agility and experimentation at Mars.
5 min read

AJ Shankar discusses the future of document review and previews exciting new features.
5 min read

Hassans leverages Everlaw to help streamline their litigation process and confront the challenges of modern ediscovery.
4 min read

Professor Delfino provides a survey of recent case law.
3 min read

The Everlaw Summit '25 agenda features panels on generative AI, legal technology, and more to help...
2 min read

Generative AI is transforming the ediscovery landscape and changing how these services are billed.
7 min read

Investigations teams walk a fine collecting complex data and privacy concerns. Our distinguished speakers share tips.
5 min read
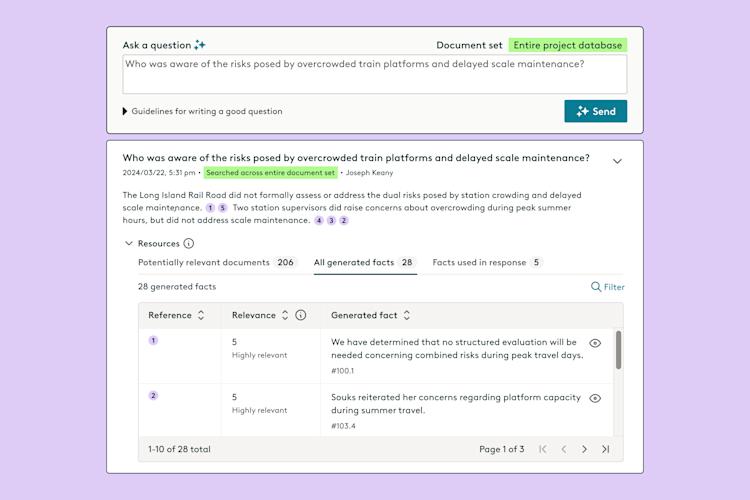
Everlaw AI Deep Dive uses generative AI to help legal professionals quickly find answers and build...
5 min read

Elizabeth Koenig discusses what GenAI means for plaintiffs' firms.
4 min read

Everlaw Summit '25 promises a great lineup of speakers and thought leaders.
2 min read

As a technology-forward firm, DiCello Levitt partners with Everlaw to keep up with modern data types...
5 min read

See how the Department of Justice gets to just outcomes, faster than ever before.
2 min read
Find out how legal professionals are using generative AI era to make a difference in their...
2 min read

Kingsley Napley leverages Everlaw to visualize their data, empower attorneys through technology, and more.
4 min read
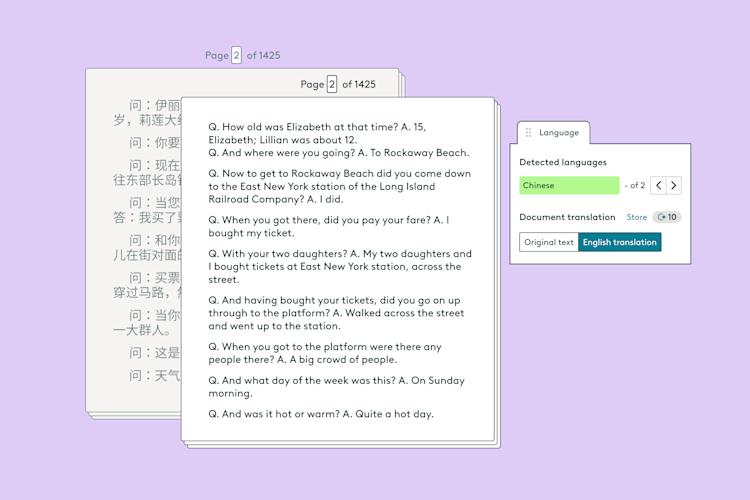
See how Everlaw Translation saves time on bulk document translations in multiple languages.
2 min read

How to find the most reliable, easy-to-use tools to handle ediscovery needs.
10 min read
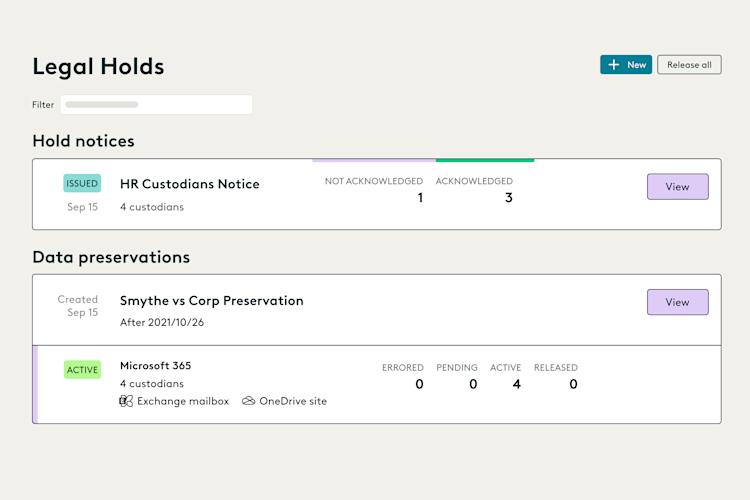
Know what can go wrong with legal holds in court.
4 min read

A critical moment has arrived for federal legal departments and the biggest blocker to overcoming it...
3 min read
This Am Law 200 firm leverages Everlaw to help fight for more business and take on...
6 min read

Professor Nancy Rapoport spoke with Everlaw about generative AI's impact on the billable hour, legal ethics,...
15 min read

Paul Noonan uses Everlaw to cut through the data deluge and reduce United Airlines' discovery costs.
4 min read

Forman Watkins uses technology like Everlaw to take on complex litigation cases.
3 min read

Get in-house metrics program tips from the experts.
4 min read

With legacy ediscovery systems lagging behind, or being abandoned altogether, now is the time to move.
3 min read

Vorys uses Everlaw to keep up with the changing nature of ediscovery.
4 min read

Know the pitfalls with ephemeral messaging before litigation.
4 min read

The creator and former host of Radiolab will deliver the Everlaw Summit '25 keynote.
1 min read

Teams are given access to vast amounts of digital information and don’t know where to start....
6 min read

The future belongs to teams that can harness both AI's potential and their human capacity for...
4 min read

Unearthing key evidene with advanced edisclosure tech.
3 min read
This Am Law 200 firm uses Everlaw to effectively process large amount of complex data and...
5 min read

How GenAI can save the day -- and the budget.
6 min read

Judge Allison Goddard spoke with Everlaw about generative AI's impact on the judiciary, how it can...
14 min read

Winning teams challenge misconceptions.
4 min read

A construction litigation law firm is able to handle complex data types and efficiently onboard contract...
5 min read

Right Discovery CEO Kevin Clark on how GenAI reduces the burden of manual review.
7 min read

How to send less data to outside counsel for review.
3 min read

The White House has spoken — and leaders should be paying close attention.
4 min read

Key considerations for preserving Slack data.
4 min read

Legal Aid at Work partnered with Everlaw for Good to seek justice for their clients.
3 min read

Creating a privilege log serves several key purposes, including compliance with discovery rules, preventing conflicts, and...
5 min read
Streamline operations, cut costs, and improve workflows with technology.
2 min read

Everlaw Staging Drive serves as a space where customers can hold pre-processing data before uploading to...
3 min read

Mastering data in minutes, rather than weeks.
2 min read

How Bracewell competes at a higher level.
4 min read

Judge James Francis (ret.) has seen the practice of ediscovery take shape throughout his career.
12 min read

The top ediscovery certification programs in 2025 can help advance your career.
5 min read

Do you know where courts land on mobile data spoliation sanctions?
6 min read

Managing ediscovery costs is more important than ever in 2025.
6 min read

Orrick cuts doc review costs by more than 50% with Everlaw AI.
3 min read

How state AGs are streamlining their ediscovery processes with advanced technology.
4 min read

Check out this alternative approach to building software.
7 min read

Cybersecurity incidents are on the rise. How can you protect your clients' most sensitive data?
2 min read

Ferguson Case Orr Patterson uses technology to put document review into overdrive.
2 min read

When uncertainty is a constant, adaptive leadership is essential.
2 min read

Check out the top access-to-justice conferences of 2025.
2 min read

Veteran sales leader joins Everlaw as new Chief Revenue Officer.
2 min read

See how this leading firm supports clients and communities throughout the world.
2 min read

Predictions for 2025 from thought leaders in the legal industry.
4 min read

Check out what the press says about our in-house counsel GenAI industry report.
4 min read

The Ninth Circuit Court of Appeals recently weighed in on the debate between inherent authority and...
4 min read

See how NY's largest public defender organization used Everlaw to promote housing rights.
2 min read

Key best practices for federal prosecutors.
4 min read

Leverage AI to elevate your in-house career with these tips.
3 min read

Leading judges on generative AI, the evolution of technology in the legal profession, and more.
8 min read

Learn how public defenders can protect due process rights throughout the discovery process.
5 min read

The Everlaw Summit Awards recognize leaders and innovators across the legal profession.
5 min read

GenAI's impact on the legal profession was a major topic at Everlaw Summit '24.
7 min read
Leveraging technology to mitigate vexatious public records requests.
2 min read

Shankar Vedantam on how unconscious bias influences legal decision making.
4 min read

Watch Everlaw founder and CEO AJ Shankar's Summit keynote.
3 min read

Generative AI is changing knowledge work – and in-house legal professionals say they see the glass...
2 min read

It’s not just about streamlining work; it’s about discovering the difference in the impact you create...
2 min read

How the Center for Justice and Accountability pursues global justice, powered by transformative technology.
4 min read

Don't miss all the exciting things happening at Everlaw Summit '24.
3 min read

Legal organizations are taking steps to prepare themselves for the generative AI era.
3 min read

Discover how in-house legal professionals view GenAI impacts on legal work and careers in this report.
2 min read
Taking on the complexities of a data explosion in the public sector.
3 min read

Judge Iain Johnston spoke with Everlaw about generative AI, what law schools need to better prepare...
12 min read

Difference Viewer is the latest release from Everlaw to help legal professionals ake charge of the...
4 min read

See how GenAI coding suggestions performed against human reviewers.
2 min read

The Everlaw Summit Awards recognize leaders in the ediscovery and legal technology space.
2 min read

Discover how legal professionals are thinking about the generative AI era in the 2024 Ediscovery Innovation...
3 min read
Gloria Lee on why she joined Everlaw, highlights from her career as a litigator, & the...
4 min read

IBM AGC Donna Haddad on the role of lawyers in the age of GenAI.
6 min read

Generative AI is already being used by attorneys and litigation support professionals in a variety of...
4 min read

Announcing the general availability of Everlaw AI Assistant.
6 min read
See how LLM prompting can augment human work to find insights in vast document sets.
3 min read

See how novel data types are changing the litigation process.
3 min read

We're bringing together the best of the legal profession at Everlaw Summit '24.
3 min read

A security regime designed to meet the unique needs of individual states.
3 min read

The VA's Michael Sarich shares insights on FOIA, AI, his vision of the future of technology...
3 min read

See how U.S. corporations cut costs by managing ediscovery in-house.
3 min read

Delve into the intricacies of managing high-volume FOIA requests in the federal government.
4 min read

See why control, budgets, and security improve with in-house consolidation of discovery.
3 min read

An effective ESI protocol is a cornerstone of modern ediscovery practices.
6 min read
How federal agencies can take a crucial step toward ensuring the security and compliance of government...
3 min read

Using performance data to rein in outside counsel costs.
3 min read

The treatment of hyperlinked files as modern attachments has become a hot-button issue in the legal...
4 min read

See how Everlaw's AI Assitant streamlines corporate in-house discovery.
4 min read

See what happens when cloud-based, easy-to-use ediscovery software like Everlaw helps create the environment for a...
5 min read

Judge Xavier Rodriguez is among the leading judges on generative AI in the law.
10 min read

Understanding the expanded preservation requirements facing federal employees.
3 min read

Staying power today means staying at the forefront of technology.
4 min read

Cross-border disputes pose unique challenges for legal professionals. Can GenAI help?
4 min read

The right ediscovery tools make responding to a subpoena request fast and efficient.
4 min read

Laurie David-Henric discusses the skills needed for success in legal ops leadership.
7 min read

See why 97% of past attendees say they'll return.
2 min read

Elizabeth Roper on protecting government agencies from cyberattacks -- and how to respond if they occur.
4 min read

AI technologies are promising to reshape evidence analysis and forensics.
2 min read
Modern tools can have a profound impact on collaborative workflows within public sector ediscovery.
3 min read

Professor Daniel Linna spoke with Everlaw about generative AI, teaching law students about legal technology, and...
18 min read

Why you should consolidate your discovery workflows into one platform for every step, from legal holds...
5 min read

Former Executive within Internal Revenue Service Criminal Investigation on change management in the public sector.
6 min read

Dr. Megan Ma discusses large language models and the role of generative AI in the law.
2 min read
Key provisions and their potential implications for government attorneys.
2 min read
The mind behind ‘Hidden Brain’ speaks on the unconscious patterns that drive human behavior at Everlaw...
2 min read

Everlaw's Multi-Matter Models lets legal teams apply previously trained predictive coding models to new cases.
3 min read

Judge Scott Schlegel has helped create one of the most technologically-advanced courtrooms in the country.
12 min read

Learn strategies and solutions for effectively managing large-scale litigation in the public sector.
5 min read

HP uses Everlaw to tame litigation costs fueled by a proliferating of corporate data.
4 min read

Bringing technology into the courtroom is essential to keep the legal system at the forefront of...
4 min read

Steve Davis, VP of Forensics & Investigations at Purpose Legal, on the biggest forensics changes, challenges,...
6 min read

The top ediscovery certification programs in 2024 can help advance your career.
4 min read

See how the San Francisco District Attorney's Office responds quickly, acts securely, and increases efficiency with...
7 min read

Federal agencies need a trusted ediscovery partner to perform at their best.
2 min read

Following these legal holds best practices reduces the risk of adverse legal outcomes, sanctions, and penalties.
5 min read

Mark your calendars for October 22-24, 2024!
1 min read

Judge Bridget McCormack spoke with Everlaw about access to justice, generative AI, alternative dispute resolution, and...
14 min read

Allensworth uses Everlaw to get to the truth, faster.
3 min read

What the federal government's new executive order on AI means for public sector legal professionals.
5 min read
Juanita Luna discusses navigating change management as Legal Ops Director at PG&E.
6 min read

An ediscovery software RFP can help in finding the best provider for your organization's needs.
5 min read

The Second Circuit weighs in on AI use (and abuse) in the courts.
3 min read

The latest releases from Everlaw help legal professionals realize the efficiency of generative AI.
4 min read
Prompting is key to maximizing the responses of large language models.
5 min read

Key TAR case law from recent years.
28 min read

AI document review is revolutionizing the legal industry.
4 min read

Bates numbering helps legal teams stay organized and on track.
4 min read

Strategies for getting ahead of the AI-driven surge in FOIA requests.
5 min read
Adams and Reese looked to Everlaw to transform their ediscovery program.
3 min read

Connect with Everlaw at Legalweek 2024.
2 min read

Everlaw CLO Shana Simmons discusses a model for corporate GenAI policies with FICO's Scott Zoldi.
3 min read
Understand Office 365 litigation hold basics and best practices and the modern legal hold tools available...
5 min read

Judge Paul Grimm speaks about the impacts of generative AI in the legal system.
13 min read

You can't prevent every attack, but you can prepare with these 4 tips.
4 min read

Managing ediscovery costs is more important than ever in 2024.
5 min read

The proposed rule change by the Fifth Circuit Court of Appeals could have far-reaching consequences for...
3 min read

Can you understand 365 days in just three numbers?
2 min read

The articles that resonated most in 2023.
6 min read

Well-planned and well-executed depositions can literally make your case in court.
13 min read

Gordon Calhoun discusses the future of generative AI and its influence on the legal profession.
4 min read

GenAI will usher in a renaissance for lawyers and legal ops professionals, and roll out unique...
6 min read

Experts share tools and techniques to help optimize the cost and accuracy of the ediscovery process.
3 min read

Everlaw founder and CEO AJ Shankar reflects on a year of GenAI innovation.
6 min read

The press found our latest in-house counsel survey compelling. See the highlight reel.
4 min read

See the three attitudes successful corporate law departments cultivate in the quest for true partnership with...
3 min read

GenAI was on everyone's minds at Everlaw Summit '23.
5 min read

Judge Paul Grimm and Dr. Maura Grossman speak on AI and its implication on the American...
5 min read

Celebrating leaders who are driving breakthroughs across their organizations and the profession.
3 min read

Strategy is everything when it comes to the successful implementation of any new technology. Here are...
4 min read
Creating a more equitable hiring process in the legal profession.
3 min read

A new hire attends Everlaw Summit '23 and takes note of all the exciting change and...
3 min read

See how in-house legal professionals rate collaboration and transparency with their partners in this new survey...
3 min read

At Everlaw Summit, Patrick Radden Keefe shares the hidden story behind the nation’s opioid crisis.
5 min read

GenAI is here to stay. Understand this transformative technology with Everlaw founder and CEO AJ Shankar.
9 min read

We've combined learning, guided practice, & verification so you can leverage your ediscovery software to its...
3 min read
Modern tech solutions let users handle the full legal holds process with much more ease, starting...
2 min read

Don't miss out on one of the best legal events of the year.
1 min read

What the best legal teams are doing today to ensure success in litigation and investigations.
3 min read

SunPower's Brad Johnston discusses building bridges between in-house legal and the business.
6 min read

Practitioners specializing in ediscovery from various state attorney general offices shared their tips.
3 min read

72 and 40: Two numbers tell the story of the legal profession at the dawn of...
3 min read

Paralegals play an essential role in helping their legal teams best find the data that can...
3 min read

Best-selling author and investigative journalist Patrick Radden Keefe to keynote Everlaw Summit '23.
2 min read

Learn how we're bringing the power of generative AI to litigation and investigations.
8 min read
Get product certified in-person with Everlaw's Reviewer and AI certifications at Everlaw Summit 2023!
1 min read

This October, we're bringing together some of the best in the profession. The Everlaw Summit awards...
2 min read

As AI takes the world by storm, litigators discuss real-life examples of its use in the...
4 min read

The explosion in new data types is driving adoption of cloud connector technologies designed for faster...
4 min read

See how Everlaw is exploring generative AI capabilities in a way that is responsible, thoughtful, and...
4 min read

Real-time collaboration tools accelerate and improve results. Here's how.
4 min read

See why Everlaw ranked #1 in multiple reports from G2, the industry-leading, peer-to-peer review site.
2 min read

See how this Am Law 50 firm uses modern technology to become a leader in innovation,...
4 min read

Everlaw Summit Awards are a celebration of legal professionals staying ahead of the curve.
2 min read

As AI eats the world, here are practical use cases from the floor of the CLOC...
3 min read

Learn how Everlaw is delivering responsible generative AI to our customers.
2 min read

Six months into the ChatGPT era, legal professionals are actively investigating generative AI's potential impact on...
3 min read

Google’s Meghan Landrum and Ironclad’s Chris Young share their approach to in-house digital transformation.
5 min read

The need is acute. The technology is here. The change-enablers are ready to go. See why...
3 min read

How Everlaw and the Leadership Council on Legal Diversity are working to build a more diverse...
3 min read

Here are four steps you can implement to protect yourself and your client information.
4 min read

Investigations teams backed by the right technology make better informed strategic decisions at every step of...
6 min read

Leaders from Google, Everlaw, and Ironclad discuss the modernization of in-house legal.
5 min read

AI was in the air at Legalweek. The consensus? AI might not replace lawyers, but lawyers...
3 min read

Harness IP's Penny Jones-Magee discusses her firm’s approach to ediscovery and the impact of choosing a...
2 min read

Dive deep into the important work UCSF is doing by making millions of opioid litigation documents...
4 min read

Everlaw announces three new features, designed to help legal professionals unearth the stories hidden between the...
5 min read

What if, instead of reading thousands of files to understand key players, we could see them...
4 min read

The great stagnation has come to an end, and the move to modern ediscovery is here.
4 min read

It’s clear that the legal teams using AI in their litigation and investigative work will gain...
4 min read

Everlaw's Director of Legal Ops & Strategy explains how to successfully ease cross-functional teams into new,...
7 min read

Meet Everlaw at Legalweek 2023 and empower your teams with the most advanced technology for ediscovery...
3 min read

See how Barnes & Thornburg, an Am Law 100 firm, transformed its approach to ediscovery with...
1 min read

See how this nonprofit is centralizing and streamlining the legal team’s mission-critical work.
5 min read

The time to lay the foundations for effective ediscovery is before you get hit by a...
7 min read

7 min read

3 min read
4 min read

1 min read

5 min read

See how the legal profession and technology are coming together to tackle the access to justice...
5 min read

Deep work is a technique used to create a sustained, distraction-free environment for focusing on demanding...
5 min read

Judges emphasized that while AI can improve efficiency, it requires human supervision, privacy protections, and high...
2 min read

The second in a series of conversations with Michael Sarich, former Director of FOIA at the...
7 min read

A Conversation with Michael Sarich, former Director of FOIA at the Department of Veterans Affairs.
7 min read

Learn about culling in ediscovery.
4 min read

Jeffries v. Harcros Chemicals Inc. set a new precedent regarding the use of open-loop AI tools...
3 min read

The three-part series is designed to bring real-world AI skills and insights to the legal aid...
3 min read

Everlaw’s Joe Skalski discusses the true value of legal services in the AI era.
7 min read

Learn about privilege protection, FRE 502(d) orders, and how to build a faster, defensible e-discovery clawback...
5 min read

Harlan Hillier DiGiacco LLP leverages Everlaw to help streamline workflows, manage metadata and ESI, and compete...
2 min read

Judge Maritza Dominguez Braswell spoke with Everlaw about AI guidance, the skills young attorneys should be...
13 min read

Learn how an effective strategy combined with cutting-edge technology can streamline the trial prep process.
12 min read

This Am Law 200 firm used Everlaw's Coding Suggestions tool to review nearly 600,000 documents, achieving...
5 min read

A partnership that helps clients succeed.
4 min read

What actually works and what defensibility really means when AI enters the discovery workflow.
5 min read

See how Coalfire’s in-house team gains command over data and delivery times.
4 min read

Hear how journalist Burt Helm used Everlaw to understand massive volumes of online video game data...
4 min read