Predictive Coding
Predictive coding, also called technology-assisted review (TAR) or computer-assisted review (CAR), utilizes machine learning algorithms to efficiently sort and prioritize documents for review in litigation or investigations.
By harnessing these algorithms, predictive coding learns from human reviewers’ coding decisions to predict how your team will evaluate the remaining, unreviewed documents. It applies those insights at scale, streamlining the review process while enhancing accuracy and consistency in identifying relevant documents. Instead of requiring attorneys to manually examine every document, the algorithm predicts which materials are likely to be responsive (relevant) or not, enabling reviewers to focus on high-priority content first.
As an analogy to illustrate, if a robot was looking for all dogs in a park, it might encounter the first dog and assume that anything with four legs, fur, and a tail is a dog. Once it encounters a cat, it must adjust that determination since a cat also has four legs, fur, and a tail. Continued training enables the model to refine its criteria for determining what’s responsive to its search until it gets to a point that additional training ceases to provide new information – the model has been trained enough to predict the rest of the evaluation set.
Supervised vs. Unsupervised Machine Learning
Supervised machine learning and unsupervised machine learning are two fundamental approaches to training machine learning models, each with distinct methods and applications. While both forms of machine learning have their place in ediscovery workflows, predictive coding utilizes supervised machine learning.
Supervised Machine Learning
Supervised machine learning involves training a model on a labeled dataset, where the input data is paired with the correct output or target labels. The model learns by finding patterns or relationships between the input data (features) and the corresponding outputs (labels). Once trained, the model can make predictions or classifications on new, unseen data.
Examples of supervised machine learning include spam detection (labeling emails as spam or not spam), image classification (labeling images based on objects they contain), and predictive coding in ediscovery (labeling documents as relevant or non-relevant).
Unsupervised Machine Learning
Unsupervised learning involves training a model on unlabeled data, meaning the model attempts to find underlying patterns, structures, or groupings in the data without prior knowledge of specific categories or labels. The model tries to learn the inherent structure of the data by analyzing relationships between features.
Examples of unsupervised machine learning include document clustering, anomaly detection, market segmentation, and dimensionality reduction.
Types of Predictive Coding Methodologies
Predictive coding methodologies vary significantly, with different approaches evolving over time. These methods, commonly known as TAR 1.0, TAR 2.0, and beyond, differ primarily in how the machine learning model is trained and applied.
TAR 1.0 (Simple Active/Passive Learning)
TAR 1.0 represents the original generation of predictive coding workflows, characterized by a separate training phase followed by an application phase. In this approach, an initial training set is selected, either through Simple Passive Learning (random sampling) or Simple Active Learning (selecting documents the system identifies as most informative). Human reviewers code these selected documents, and the system is trained accordingly.
To evaluate the model's performance, a separate control set – pre-coded by humans and set aside from the start – is used to determine when the model has achieved satisfactory accuracy. Through a series of iterative training rounds (for example, Judge Peck’s protocol in Da Silva Moore involved seven rounds of training), the model is refined until further training produces minimal improvements. At that point, training is considered complete, or “locked,” and the system proceeds to classify the entire document collection.
In TAR 1.0 workflows, machine learning ceases to update once the review phase begins. Documents predicted as relevant are typically reviewed by humans for verification and privilege screening, while those predicted as non-relevant may be excluded from individual review.
TAR 1.0 was the dominant methodology in early court cases and tools, relying heavily on comprehensive up-front training that often involved large random samples with a defined endpoint where the model’s training was declared complete.
TAR 2.0 (Continuous Active Learning)
TAR 2.0 is a more advanced and adaptable approach that gained popularity in the mid-2010s, primarily associated with continuous active learning (CAL). Unlike TAR 1.0, TAR 2.0 eliminates a fixed training phase – learning continues dynamically throughout the entire review process. The software continually updates and reprioritizes documents as reviewers code more items.
In a typical CAL workflow, the system presents the reviewer with the document most likely to be relevant next. Once the reviewer codes it, the model immediately updates and reprioritizes the remaining documents. This iterative process continues until relevant documents become rare or are no longer being found.
CAL workflows do not require a pre-defined control set. Instead of relying on a one-time recall estimate, the process progresses until it reaches a point of saturation. TAR 2.0 offers several advantages: it is often more efficient when relevant documents are scarce since it constantly targets the most likely relevant documents, and eliminates the need for reviewing a large random control set purely for statistical measurement.
CAL protocols have largely replaced TAR 1.0 for many organizations due to their efficiency and responsiveness. The approach ensures constant interaction between the algorithm and human reviewers – every decision made by a reviewer helps retrain the model, while the model’s refined predictions guide reviewers to the most critical documents. This process continues until virtually all likely-relevant documents have been identified.
TAR 3.0 (Emerging Approaches)
The term TAR 3.0 is sometimes used to describe the latest advancements in predictive coding. While there is no universally accepted TAR 3.0 methodology yet, one emerging approach involves blending continuous learning with intelligent document clustering.
For example, a TAR 3.0 workflow might apply a clustering algorithm to group documents by topic, then use CAL specifically on cluster centers – representative documents from each group. This strategy aims to ensure comprehensive training by covering all themes within the collection, reducing the risk that CAL might overlook rare but important topics. Once no more relevant cluster centers are identified, the model is considered well-trained and ready to predict relevance across the entire dataset.
TAR 3.0 strives to enhance efficiency and consistency by strategically distributing training across the dataset’s conceptual landscape. These methods aim to address potential blind spots by leveraging data organization techniques in conjunction with active learning. While still evolving, TAR 3.0 approaches promise even greater effectiveness in AI-assisted review, potentially incorporating advanced technologies such as neural networks or large language models in the future.
Key Steps in a Typical Predictive Coding Process
Specific workflows can vary, however a typical predictive coding process often follows a common series of steps.
1. Initial Training
A subject matter expert (SME) or seasoned attorney reviews a sample of documents known as the training set or “seed set”, drawn from the overall collection. This seed set is designed to be a representative snapshot of the data, encompassing a diverse range of document types. Each document within the set is manually classified as relevant or not relevant to the matter at hand.
Ensuring the quality of this training set is essential – it should be comprehensive and reflect the variety within the entire collection. Depending on the approach, the seed set may consist of randomly chosen documents (Simple Passive Learning) or documents identified by the system as having a high likelihood of relevance (Simple Active Learning). The SME’s consistent and informed coding serves as the foundational teaching signal for the algorithm.
2. Algorithm Learning
The predictive coding software processes the human-coded seed set to train a machine learning model. This training often involves algorithms such as logistic regression, support vector machines, or other text classification techniques.
By analyzing patterns within the text and metadata of documents labeled as relevant or not relevant, the system builds an internal model – often referred to as a “relevance model” or classifier – that can estimate the likelihood of relevance for other documents. At this point, the model learns which features (such as words, phrases, and metadata) differentiate relevant documents from non-relevant ones within the specific context of the case.
3. Initial Prediction and Ranking
The trained model is then applied to the uncoded documents across the broader collection. The software generates a relevance score for each document based on the model’s predictions. Documents can be ranked or filtered according to these scores, typically producing a list ordered from most likely relevant to least likely.
At this stage, the review team can use the prediction results to inform their next steps. For instance, they may choose to review all documents above a specific score threshold or prioritize the highest-ranked documents first – a process known as prioritized review. Documents with lower scores, predicted to be mostly irrelevant, may be set aside to be reviewed later or not at all if they are deemed highly unlikely to be responsive.
4. Iterative Training and Validation
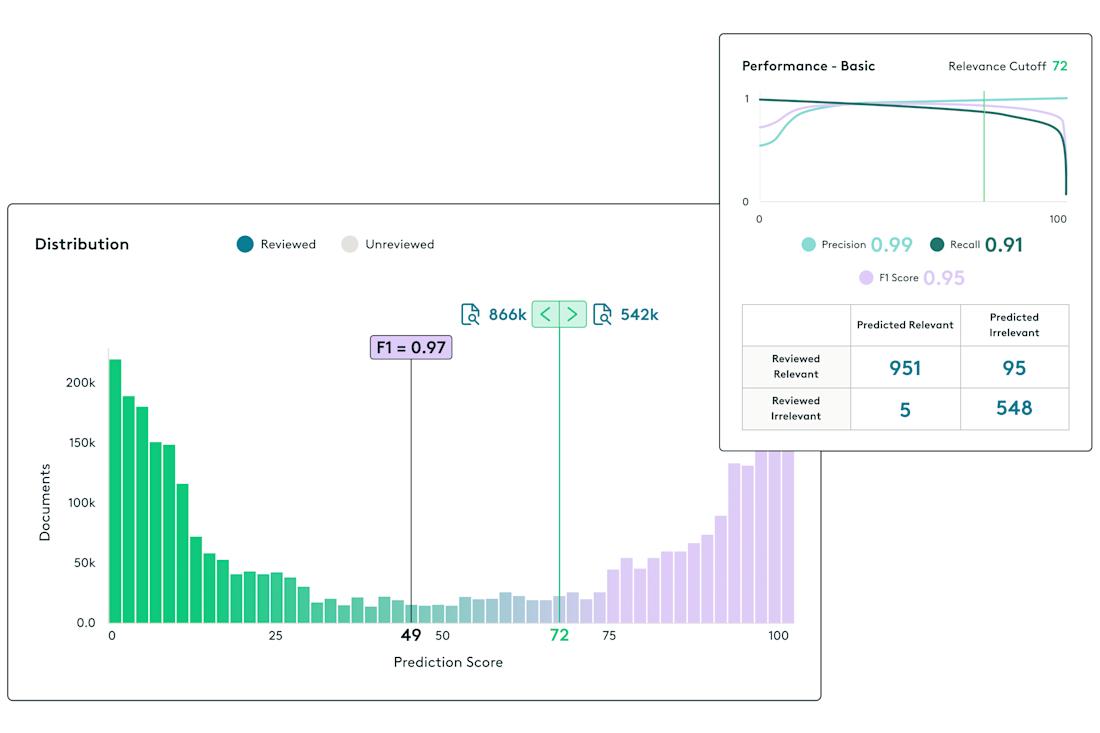
Predictive coding typically follows an iterative, feedback-driven approach. Once the initial model is built, reviewers often conduct additional training rounds to enhance accuracy. They may review a new batch of documents – either randomly selected or those the system finds ambiguous – and incorporate their coding decisions back into the model for further refinement. This cycle continues until the model reaches stability, meaning additional training produces minimal improvement.
Quality control (QC) checks are conducted throughout the process, often using a control set or continuous sampling to assess the model’s recall and precision after each round. The goal is to ensure the system is effectively identifying a sufficiently high percentage of relevant documents. If metrics or spot-checks reveal gaps in performance, further training is conducted. If the model’s performance meets acceptable standards, the training process can be concluded.
5. Categorization and Review
Once the model is stabilized and validated, it categorizes the remaining documents based on its predictions. The workflow typically directs human reviewers to assess the highest-ranked documents to make final relevance determinations. Different TAR protocols manage this process in distinct ways.
For example, in a one-time training approach (TAR 1.0), the model is trained once and then used to auto-code the entire collection. Reviewers may then manually QC only the documents predicted as relevant. In continuous training approaches (TAR 2.0), the review process itself serves as ongoing training. Reviewers continuously validate relevance during their review, refining the model in real-time until most high-scoring documents have been reviewed.
In either approach, documents are not produced to the opposing party without human oversight to confirm relevance and privilege status. While predictive coding assists in prioritizing and filtering documents, final production usually requires human verification of relevant documents, particularly those scoring above the established cutoff threshold.
6. Final Quality Check
To ensure defensibility, teams typically conduct a final QC check, which often involves reviewing a random sample of documents predicted to be non-relevant. This step helps confirm that the algorithm did not overlook any obviously relevant documents.
If a significant number of relevant documents are discovered during this spot-check, it may indicate that the model has not achieved the desired recall, requiring additional training rounds or adjustment of the cutoff threshold. If the rate of false negatives is acceptably low, the remaining low-scoring documents can be classified as non-responsive and excluded from production, significantly reducing the review workload.

Notable Case Law Rulings Involving Predictive Coding
While the use of TAR in discovery has become commonplace, that wasn’t always the case. Adoption of TAR accelerated with the first case to approve the use of TAR – Da Silva Moore – in 2012. However, there are still disputes on whether TAR should be required in cases, whether parties can switch to using TAR in the middle of a case, who pays for TAR if the requesting party advocates for a specific approach and more.
Da Silva Moore v. Publicis Groupe & MSL Group, No. 11 Civ. 1279 (ALC) (AJP) (S.D.N.Y. Feb. 24, 2012)
This historic ruling by New York Judge Andrew J. Peck was the first case in which a Court approved the use of computer-assisted review.
After instructing the parties to submit proposals to adopt a protocol for ediscovery that includes the use of predictive coding, Judge Peck issued an opinion that approved of the use of “computer-assisted review” of ESI for this case, making it likely the first case to recognize that “computer-assisted review is an acceptable way to search for relevant ESI in appropriate cases.” Today, the use of predictive coding has become common, especially in cases involving large ESI collections.
Hyles v. New York City, No. 10 Civ. 3119 (AT)(AJP) (S.D.N.Y. Aug. 1, 2016)
Citing Sedona Principle 6 (“Responding parties are best situated to evaluate the procedures, methodologies, and technologies appropriate for preserving and producing their own electronically stored information.”), Judge Peck refused to order the defendant to use TAR against their wishes, stating “The short answer is a decisive ‘NO.’”
Lawson v. Spirit Aerosystems, Inc., No. 18-1100-EFM-ADM (D. Kan. June 18, 2020)
Kansas Magistrate Judge Angel D. Mitchell granted the defendant’s Motion to Shift Costs of Technology Assisted Review of ESI to the plaintiff, ruling “the ESI/TAR process became disproportionate to the needs of the case” after having previously warned the plaintiff that inability to focus ESI requests would result in the court shifting costs.
Livingston v. City of Chicago, No. 16 CV 10156, (N.D. Ill. Sept. 3, 2020)
Illinois Magistrate Judge Young B. Kim denied the plaintiffs’ motion to force the defendant to either use agreed-upon search terms to identify responsive documents and then perform a manual review for privilege or use TAR on the entire ESI collection with an agreed-upon coding system for responsiveness instead of the defendant’s proposed TAR protocol to use TAR to identify responsive documents from the documents retrieved by the search terms.
Edgar v. Teva A Pharm. Indus., Ltd., No. 22-cv-2501-DDC-TJJ (D. Kan. Aug. 5, 2024)
Kansas Magistrate Judge Teresa J. James entered the parties’ proposed ESI protocol with Plaintiffs’ proposed TAR provision that first required a “good faith attempt to produce from the search term protocol” before a producing party could disclose the need for the implementation of TAR. This case illustrates how – more than a dozen years after the Da Silva Moore ruling – parties are not only disputing how TAR should be conducted, but also whether it should even be conducted at all.
Benefits of Predictive Coding
Despite the continued case law disputes, predictive coding offers numerous benefits in the ediscovery review process, combining the strengths of human expertise and machine efficiency. By efficiently reducing data volumes early on through the exclusion of irrelevant material, predictive coding also streamlines subsequent phases of litigation, such as depositions and trial preparation, by minimizing the amount of “junk” that progresses through the process. This approach helps meet discovery obligations that might otherwise be limited or disputed due to undue burden.
Efficiency and Speed
A major advantage of predictive coding is its ability to drastically speed up the document review process. By allowing the AI algorithm to handle the bulk of data sorting, legal teams can concentrate their manual review efforts on a smaller, highly relevant subset of documents. Prioritizing likely relevant documents early enables attorneys to uncover critical facts sooner and meet discovery deadlines with greater ease. Accelerating the review process not only saves time but also offers strategic benefits by revealing key evidence early in litigation.
Cost Reduction
Predictive coding significantly reduces the number of documents requiring manual review, resulting in substantial cost savings. Since attorney review time is typically the most expensive aspect of discovery, minimizing the time spent on irrelevant materials can drastically lower costs.
For example, in Brown v. BCA Trading, predictive coding was estimated to save approximately £120,000 compared to traditional linear review. By effectively filtering out non-relevant documents, fewer contract attorney or outside counsel hours are necessary.
Accuracy and Recall
When properly implemented, predictive coding can achieve higher accuracy than manual review alone. Human reviewers are prone to errors – fatigue, inconsistency, and oversight can result in missed relevant documents. In contrast, predictive coding applies consistent criteria across the entire dataset and doesn't suffer from fatigue. This consistency often leads to higher recall (identifying more relevant documents) and greater precision compared to manual review.
In Pyrrho Investments Ltd v MWB Property Ltd., the High Court acknowledged evidence suggesting that predictive coding produces results that are at least as accurate as human review, if not more so. Additionally, because the algorithm’s model is built from the expertise of senior reviewers, it effectively scales their knowledge across the entire dataset. This approach can help identify subtle yet relevant documents that less experienced reviewers might overlook.
Consistency
In large-scale projects involving multiple human reviewers, inconsistency in coding is a well-known challenge – different reviewers may apply varying relevance judgments to the same document. Predictive coding significantly improves consistency by evaluating each document against the same learned model, ensuring uniform application of criteria.
As Master Matthews noted in Pyrrho Investments, using software to apply a single senior lawyer’s approach results in “greater consistency in the review compared to using multiple lower-grade reviewers” working independently. Enhanced consistency reduces the likelihood of relevant documents being missed due to subjective judgment or human error. Additionally, it strengthens defensibility, as parties can demonstrate that the machine applied systematic, consistent standards when including or excluding documents.
Resource Allocation and Focus
Predictive coding automates much of the document culling process, allowing human reviewers to focus on tasks that genuinely require legal expertise. Attorneys can dedicate more time to in-depth analysis of key documents, refining case strategy, or examining truly ambiguous or borderline cases, rather than sifting through countless irrelevant files.
This more strategic use of attorney time adds meaningful value to the case. Additionally, by prioritizing likely relevant documents, lawyers can quickly uncover critical evidence or “smoking guns,” which can influence case strategy or support early settlements.
Proportionality and Manageability
Predictive coding enables parties to conduct discovery in a proportionate manner, as encouraged by civil procedure rules. It makes reviewing large data sets – such as a million-document collection – feasible, where manual review would be prohibitively expensive. Courts have acknowledged this advantage.
For example, in Pyrrho, the court considered proportionality, noting that while tens of millions of pounds were at stake, conducting a multi-million document review using TAR was reasonable, whereas a full manual review would not be.
Concerns and Challenges with Predictive Coding
Unfortunately, despite its significant advantages, predictive coding in ediscovery comes with a set of concerns and challenges that legal teams and courts must navigate, spanning technical, legal, and practical domains.
Understanding and Trusting the Technology
Predictive coding can seem like a “black box” to attorneys and judges not versed in statistics or machine learning. Many lawyers have traditionally been cautious of new technology, and TAR is no exception. A common challenge is simply a lack of understanding or trust – attorneys may worry about how the algorithm is making decisions and whether it could miss something important.
This concern is heightened by the fact that machine learning models typically lack transparent, readable explanations for their decisions. Consequently, some lawyers feel uneasy about relying on a process they don’t fully understand. Bridging this gap typically requires education, demonstrations, and familiarity with the technology.
The encouraging news is that modern TAR platforms are increasingly user-friendly, and as legal professionals gain more experience, the intimidation factor is gradually fading.
Legal Defensibility and Transparency
Concerns have arisen over the level of transparency and cooperation required when using TAR. Early cases like Da Silva Moore and In re Actos encouraged parties to be highly transparent – sometimes even sharing seed sets or involving opposing counsel in the training process. This raised fears that using TAR might compel a producing party to “show its work” more than traditional manual review, where such openness is not expected. For instance, revealing a seed set allows the opposing side to see how documents were marked as relevant or not, potentially exposing legal strategy or inviting unwarranted scrutiny.
The worry is that if courts impose excessive cooperation requirements (beyond what Rule 26 mandates) as a condition for using TAR, it could discourage its adoption. However, more recent case law, such as Rio Tinto and Hyles, has generally favored a more balanced approach, emphasizing that TAR should be held to the same standard as any other discovery method – not a stricter one.
Despite this trend, producing parties still face strategic decisions about how much transparency to provide – such as whether to agree on validation metrics with the opposing party, disclose the non-relevant rate, or share process details. The challenge lies in building trust with the opposing side and the court without revealing sensitive work product or inviting protracted discovery disputes. To bolster defensibility, best practices include thoroughly documenting the process, validating results with statistical analysis, and, if necessary, involving a neutral expert to confirm the effectiveness of the TAR approach.
Black Box Algorithm and Explainability
A key aspect of defensibility is the black box problem, which is the difficulty in interpreting how machine learning models arrive at their decisions. The internal workings of the model are not easily understandable, meaning neither users nor the court can precisely explain why the algorithm classified Document X as irrelevant, for example. The model functions as a probabilistic system that has “learned” from prior examples, which can create discomfort and uncertainty.
The black box concern has prompted some parties to seek transparency into the training process or demand the use of control sets and metrics to validate TAR’s effectiveness. In practice, this challenge is addressed by applying statistical sampling to validate results – for example, demonstrating with 95% confidence that no more than X% of relevant documents were missed. These metrics can offer reassurance to the court without requiring an in-depth understanding of the algorithm’s inner workings.
Additionally, advancements in AI and the concept of explainable AI may eventually offer greater transparency. However, traditional TAR tools have generally provided limited explanations beyond document ranking. For now, legal teams must be prepared to explain TAR to non-technical audiences effectively, emphasizing validated outcomes and statistical reliability rather than the complexities of the underlying algorithms.
Training Bias
The effectiveness of predictive coding relies heavily on the quality of human training. Ensuring that seed or training sets are comprehensive, accurate, and unbiased is a significant challenge. If the reviewers' judgments are flawed or if the training set fails to capture the diversity of the document population, the model can become skewed or overlook entire categories of relevant information. This issue, often referred to as the “garbage in, garbage out” problem, highlights that the algorithm’s performance is only as good as the data it learns from.
For example, if a SME mistakenly labels all documents related to a specific sub-topic as not relevant – perhaps due to a misunderstanding of the case – the model might undervalue that sub-topic and fail to identify relevant documents related to it. Likewise, if relevant documents on a niche issue are absent from the training set, the model may not recognize or prioritize them.
This underscores the importance of skill and diligence in selecting and coding training documents. Predictive coding is not a fully automated process – ongoing oversight, testing, and refinement are essential to prevent the model from drifting off course. Bias in training is also a concern; if the model is trained exclusively on documents from a single custodian or time frame, it may not generalize well to others.
The challenge is to curate training data that is diverse, accurately labeled, and representative of the entire collection. Best practices such as iterative active learning and incorporating random samples to ensure broader coverage can help mitigate these risks. However, TAR is not foolproof – if improperly trained, it can miss critical information. Attorneys must remain vigilant by performing quality control checks on excluded documents to ensure important material is not overlooked due to training bias.
Technical and Resource Hurdles
Implementing predictive coding effectively requires the right technology and expertise. High-quality TAR software can be costly, and not all law firms or clients have access to it or are willing to invest in it upfront. Additionally, there is a learning curve involved in properly setting up and managing a TAR project, such as understanding how to interpret model results, knowing when to stop training, and validating outcomes. Smaller firms or those with limited IT support may struggle to adopt the technology.
TAR is also most effective with larger data sets – if the collection is small, such as a few thousand documents, the effort and cost of training a model may not be justified. Determining when predictive coding is appropriate is an important consideration.
Another technical hurdle involves handling non-text data. While TAR excels with emails and text documents, it can struggle with images, scanned PDFs, foreign languages, or embedded data. Traditional predictive coding systems may overlook these types of data or require additional preprocessing steps, such as OCR for scans or translation for foreign languages. If a case involves a significant amount of such data, TAR can become less effective or require more complex workflows.

Furthermore, TAR platforms vary – each may employ different algorithms or workflows. For instance, one tool might rely on logistic regression, while another uses a proprietary algorithm. Although the fundamental principles are similar, these differences can influence results. Some systems require manual cutoff score adjustments, while others provide automated recommendations. Misusing the software or misunderstanding its nuances can lead to suboptimal outcomes.
In essence, effective use of predictive coding depends on having both the right technology and skilled human operators. Ensuring both components are in place is essential for successful implementation.
Best Practices for Implementing Predictive Coding
To optimize the advantages and minimize the risks associated with predictive coding, practitioners have established a set of best practices. These recommendations are designed to ensure that a TAR project is conducted efficiently, effectively, and in a defensible manner. Below are several recommended best practices for implementing predictive coding in your organization:
Start with a Plan
Approach predictive coding as a structured, managed process rather than a plug-and-play solution. Before starting, establish a clear protocol detailing how training, validation, and QC will be conducted. Set specific goals, such as desired recall or precision levels, and determine how progress will be measured. Throughout the project, remain actively involved – avoid setting the software on autopilot.
Legal teams must actively guide the algorithm through feedback and determine when training can be concluded. Maintaining a diligent, hands-on approach helps identify issues early and enhances the overall effectiveness of the process.
Avoid Concern with Quality Training Data
Since the model’s effectiveness relies heavily on proper training, it’s essential to approach the training phase with diligence and precision. Involve SMEs to perform the seed coding to ensure that decisions are accurate, informed, and reflect the nuances of the case. Make sure to address the full range of relevant issues by providing the algorithm with examples from all pertinent categories, including edge cases.
A recommended approach is to start with a diverse set of documents – combining high-relevance documents (if known), random samples, and potentially some null set documents – to provide a broad foundation. When using active learning, allow the system to suggest documents after the initial seed phase to ensure training focuses on those that will most enhance the model’s performance.
Be mindful of systemic bias. Avoid training exclusively on certain sources, such as emails from executives, while neglecting communications from lower-level employees, as this could skew the model’s understanding of relevance. If the collection includes multilingual documents or scanned files, ensure these are properly processed (through translation or OCR) and incorporated into training.
Leverage Keyword Search and Other Tools Complementarily
Predictive coding doesn’t require abandoning traditional methods altogether. In fact, integrating TAR with keyword filtering and other culling techniques can be highly effective. For instance, you can apply date range filters or custodian scoping to reduce the dataset before applying TAR. Additionally, keyword searches can be used to validate TAR results by running key terms across the dataset and assessing whether TAR properly flagged those hits.
If you discover relevant documents through keyword searches that TAR scored low, it’s a sign to include them in further training. On the other hand, if TAR is surfacing off-topic documents, you can refine the process by using keywords to exclude irrelevant clusters. Utilizing keyword searches as both a diagnostic tool and safety net can enhance the TAR process.
Similarly, other analytics tools like email threading and clustering can complement TAR. For example, threading emails before ranking them with TAR can streamline the review process. TAR works best as part of a comprehensive workflow; it doesn’t have to be the sole method. By cross-referencing TAR’s results with keyword searches and other techniques, you can uncover blind spots and ensure the system is performing effectively.
Document Your Process and Decisions
Comprehensive documentation is essential for defensibility. Maintain detailed records of how training sets were selected, the number of training rounds conducted, validation results at each stage, and the criteria used for determining when to stop training or set cutoffs. If you employed a control set, preserve those results; if you relied on continuous review of high-scoring documents until reaching a threshold, document when the yield diminished.
Also, track any disagreements or challenges (such as conflicts among SMEs about specific documents) and how those issues were resolved. If the court or opposing party later asks questions about your TAR process, you will have a clear, step-by-step account to provide. This transparency, even if disclosed retroactively upon request, enhances both trust and defensibility. It also ensures continuity if a key team member departs, preventing the need to duplicate efforts.
In some instances, parties have even agreed to share certain aspects of their TAR process documentation to avoid disputes or motions. At a minimum, maintain a project log that outlines the TAR workflow. Additionally, consider recording the rationale behind critical decisions, such as why training was concluded at a specific point or how relevance cutoffs were established.
Perform Validation and Quality Control at Multiple Points
Best practices recommend statistically validating TAR results to ensure accuracy and defensibility. This typically involves random sampling of both the “relevant” set and the “discarded” set to assess recall and precision. For instance, sampling documents the model classified as not relevant helps estimate the proportion that might actually be relevant (false negatives).
It is also important to validate the consistency of reviewer coding, especially when multiple reviewers are involved in training. High disagreement rates may indicate the need for calibration. Many TAR protocols establish that if recall falls below a predetermined threshold, additional corrective measures will be taken. Even if not explicitly required, performing such validation internally is a prudent practice.
QC checks enhance confidence in the process. These may include manually reviewing a random sample of low-scoring documents, spot-checking high-scoring documents to confirm correct inclusions, and verifying that known relevant documents are being identified by the model. Courts do not demand perfection, but they do expect reasonable validation that the TAR process was effective.
The guiding principle is “trust but verify” – leverage the efficiency of TAR while applying thorough validation using established statistical methods and professional judgment. This balanced approach of automation complemented by human oversight is essential to building a defensible TAR process.
Educate and Train Your Team
Ensure that the legal team operating the TAR software is well-trained on the specific tool being used and thoroughly understands TAR concepts. Invest time in training the team before – and throughout – the process of training the algorithm. Many TAR errors occur because users misinterpret the software’s metrics or are unsure how to respond to certain outputs.
It is best practice to conduct a small pilot project, review the tool’s documentation, and study relevant use cases. If necessary, consult with an ediscovery expert or utilize the software provider’s support during your initial implementation of TAR. Additionally, be prepared to educate opposing counsel and the judge if they are unfamiliar with TAR. This may include providing a clear, concise explanation of how TAR works, why it is appropriate for the case, and its proportionality benefits.
Offering a stipulated TAR protocol or a joint submission outlining its use can also help prevent objections. Familiarity among all stakeholders leads to a smoother process. Internally, ensure that review teams understand how TAR will impact their workflow – such as reviewing documents based on priority rather than sequentially through a custodian’s files.
Choose the Right Tool and Settings
Select a well-established TAR platform that suits your specific requirements. For example, some excel at continuous learning, while others are better for one-time training. Some are optimized for multilingual data, and others offer user-friendly interfaces that enhance reviewer productivity. Carefully assess your options and choose the tool that aligns best with your needs.
Once you have selected the software, configure it thoughtfully. This includes deciding on the appropriate coding scheme – whether choosing a simple binary classification (relevant/not relevant) or a more nuanced tagging approach. Also, determine whether to use a separate control set or rely on implicit continuous validation. Invest in technology which strikes a balance between power and ease of use for your team.
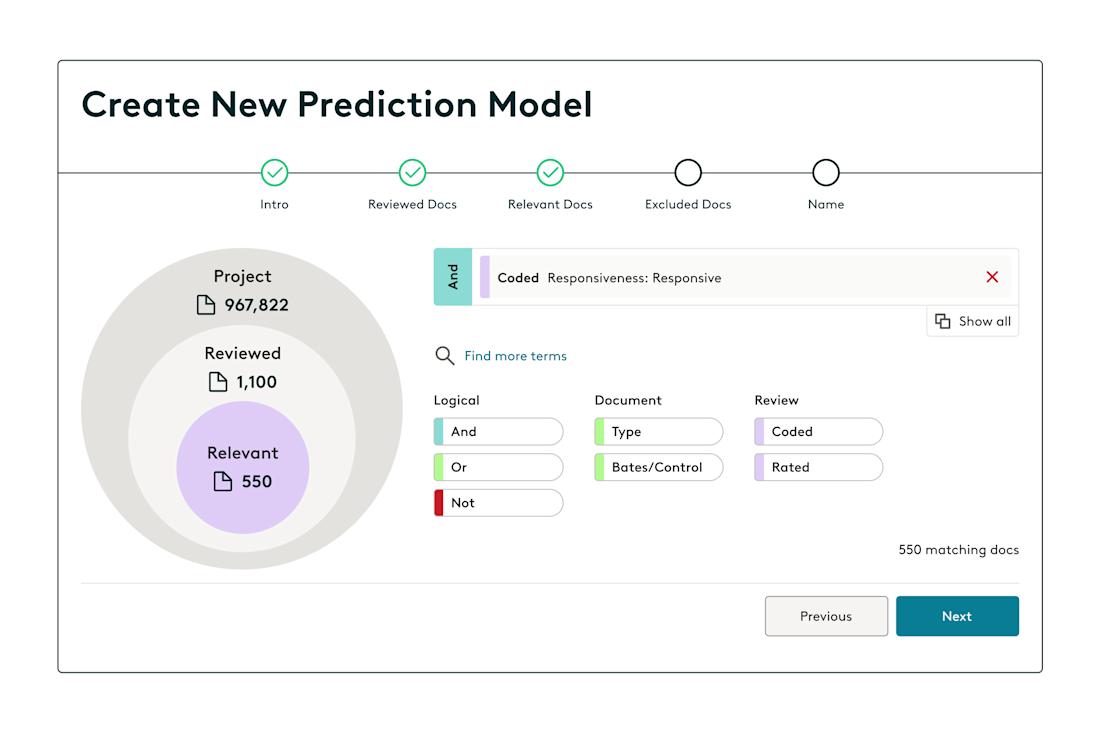
If possible, conduct a preliminary test or simulation to refine your approach before fully implementing TAR. Best practices often recommend having contingency plans – such as switching tools, adjusting methodologies, or incorporating more manual review for specific subsets – if results are unsatisfactory.
Ultimately, the effectiveness of predictive coding depends on selecting the right software and properly configuring the process to meet the demands of your case. When the appropriate tool is well-tuned, your document review will be significantly more seamless, efficient, and effective.
Cooperate and Communicate
Predictive coding should not be used as a surprise tactic in discovery. It is most effective when both parties engage in open communication about its use. Collaborate with opposing counsel as reasonably as possible, including discussing the use of TAR during the Rule 26(f) conference or discovery planning phase. Clearly state your intention to use TAR and outline the general protocol, without necessarily disclosing specific seed content.
Negotiating aspects like statistical sample sizes for validation or whether to share recall estimates can prevent disputes before they arise. This proactive approach aligns with the principles of The Sedona Conference’s Cooperation Proclamation. Additionally, if unexpected issues emerge during the TAR process – such as discovering a new set of data that may require separate handling – address them collaboratively rather than making unilateral decisions that could be contentious.
Ultimately, successful TAR implementation is not just about technology: it’s about collaboration and finding common ground to address discovery challenges effectively.


